-
Interface Summary Interface Description Former Formats a double or complex (double[]) into a string (like sprintf in C). -
Class Summary Class Description AbstractFormatter Abstract base class for flexible, well human readable matrix print formatting.AbstractMatrix Abstract base class for arbitrary-dimensional matrices holding objects or primitive data types such asint,float, etc.AbstractMatrix1D Abstract base class for 1-d matrices (aka vectors) holding objects or primitive data types such asint,double, etc.AbstractMatrix2D Abstract base class for 2-d matrices holding objects or primitive data types such asint,double, etc.AbstractMatrix3D Abstract base class for 3-d matrices holding objects or primitive data types such asint,double, etc.FormerFactory Factory producing implementations ofFormervia method create(); Serves to isolate the interface of String formatting from the actual implementation. -
Enum Summary Enum Description Norm Types of matrix norms.Transpose Transpose enumeration
Package cern.colt.matrix Description
Getting Started
- Overview
- Introduction
- Semantics of Views
- Functional Programming with Objects
- Algorithms
- Linear Algebra
- Orthogonality and Polymorphism
- Package Organization, Naming Conventions, Policies
- Performance
- Notes
1. Overview
The matrix package offers flexible object oriented abstractions modelling multi-dimensional arrays, resembling the way they can be manipulated in Fortran. It is designed to be scalable, not only in terms of performance and memory requirements, but also in terms of the number of operations that make sense on such data structures. Features include
|
|
||||||||
|
|
||||||||
|
|
||||||||
|
|
||||||||
File-based I/O can be achieved through the standard Java-built-in serialization
mechanism. All classes implement the Serializable interface.
However, the toolkit is entirely decoupled from advanced I/O and visualisation
techniques. It provides data structures and algorithms only.
This toolkit borrows many fundamental concepts and terminology from the IBM Array package written by Jose Moreira, Marc Snir and Sam Midkiff. They introduced well designed multi-dimensional arrays to the Java world.
Back to Overview
2. Introduction
Multi-dimensional arrays are arguably the most frequently used abstraction in scientific and technical codes. They support a broad variety of applications in the domain of Physics, Linear Algebra, Computational Fluid Dynamics, Relational Algebra, Statistics, Graphics Rendering and others. For example many physics problems can be mapped to matrix problems: Linear and nonlinear systems of equations, linear differential equations, quantum mechanical eigenvalue problems, Tensors, etc. Physics NTuples are essentially 2-d arrays. In the area of Online Analytic Processing (OLAP) multi-dimensional arrays are called Data Cubes. In this toolkit they are called Matrices, simply because the term Array is already heavily overloaded and Data Cube is somewhat fuzzy to many people.
Matrices are basically rectangular grids with each cell in the grid containing a single value. Cells are accessed via zero-based integer indexes. Matrices can be characterized by
- Rank: The number of dimensions (axes). Most frequently used are one and two dimensions.
- Shape: Each dimension has a certain number of slots. All slots together make up the shape. For example, a 2-dimensional 10 x 50 matrix has 10 slots along its first dimension, and 50 slots along its second dimension, yielding 500 cells.
- Value type: The type of value to be stored in each cell. Can be integer, floating point or an arbitrary object.
Here is an example of a 8x8x8 matrix and other matrices.
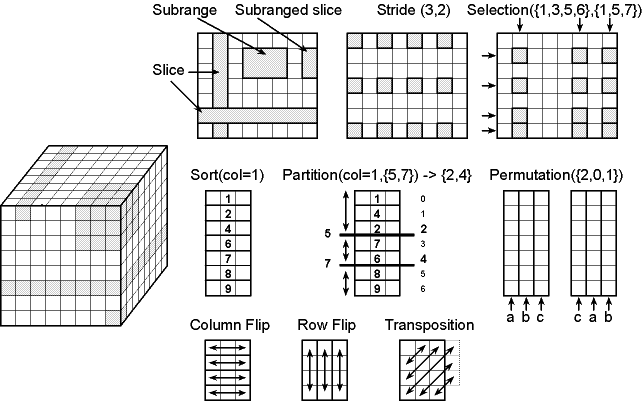
As broad as the spectrum of applications using multi-dimensional matrices is the number of operations meaningful on them. Only a smallish subset of those operations are provided in this library. We hope that this will change over time. However, core multi-purpose functionality such as subrange, slice, dice, flip, stride, selection and sort views as well as copying and numerical transformations (*,/,+,-,...) are efficiently provided. The primary motivation for views is ease-of-use. Views allow to express otherwise complex aggregate operations in simple terms. They seek to present a matrix in different ways to a user and/or functions operating on a matrix. Subranging, slicing, dicing, flipping, striding, selecting and sorting are virtual transformations: they merely alter the way we see the same data. They produce views, which are objects that know only about certain regions of the entire matrix. Views all point to the same data, so changes in the view are reflected in the original matrix, all other possibly nested views of the original matrix, and vice-versa. Pete and Jane can look at a flower in many different ways although it remains one single flower. If Pete steps on top of the flower, Jane will certainly note. Which is not the case when copying is applied, since it is a materializing transformation. It means, the connection between the original and the copy is lost. If Pete is stepping on top of a rose and Jane is admiring another one, it won't have any impact on her. Views can arbitrarily be nested. They eliminate the need for explicit region operations. Any operation on a matrix can be used as a region restricted operation by operating on a matrix view instead of the whole matrix. Here are some examples:
| Lets construct a dense 3 x 4 matrix | |
|
DoubleMatrix2D matrix; |
3 x 4 matrix: 0 0 0 0 0 0 0 0 0 0 0 0 |
| We can get rid of the typed distinction between sparse and dense matrices. Use a factory, as follows | |
|
DoubleFactory2D factory; |
3 x 4 matrix: 0 0 0 0 0 0 0 0 0 0 0 0 |
| The shape can be retrieved with int rows = matrix.rows(); int columns = matrix.columns(); |
|
| We set and get a cell value: | |
|
int row = 2, column = 0; |
3 x 4 matrix 0 0 0 0 0 0 0 0 7 0 0 0 |
| Looping is done as expected: | |
double sum = 0;
for (int row=rows; --row >= 0; ) {
for (int column=columns; --column >= 0; ) {
sum += matrix.get(row,column); // bounds check
//sum += matrix.getQuick(row,column); // no bounds check
}
}
System.out.println(sum);
|
|
| The following idiom uses a subranging view to set all cells of the box
starting at [1,0] with width and height of 2 to the value 1: |
|
| matrix.viewPart(1,0,2,2).assign(1); System.out.println(matrix); |
3 x 4 matrix 0 0 0 0 1 1 0 0 1 1 0 0 |
|
A dicing view can be used to print the matrix in a different format (4 x 3). This is equivalent to a zero-copy transposition: |
|
| System.out.println(matrix.viewDice()) | 4 x 3 matrix 0 1 1 0 1 1 0 0 0 0 0 0 |
|
Next, a flipping view mirrors the matrix. |
|
| System.out.println(matrix.viewColumnFlip()); | 3 x 4 matrix 0 0 0 0 0 0 1 1 0 0 1 1 |
|
A slicing view shows the second row, a 1-dimensional matrix: |
|
| System.out.println(matrix.viewRow(1)); | 4 matrix 1 1 0 0 |
|
Note that the result of a slicing operation is not a 2-d matrix with
one row, but a true 1-d type with all capabilities of the type,
namely The slicing view is now fed into some external algorithm expecting a
1-dimensional matrix: |
|
| If the algorithm is designed such that it modifies data of the row, but we want to avoid any side-effects, we can feed it a copy of the row: someAlgorithm(matrix.viewRow(1).copy()); |
|
| A stride view shows every row and every second column. It is useful for scatter/gather operations. | |
| System.out.println(matrix.viewStrides(1,2)); | 3 x 2 matrix 0 0 1 0 1 0 |
| A selection view shows explicitly specified rows and columns. Imagine a 2-d matrix. Columns are attributes energy, tracks, momentum, the rows hold N such measurements, as recorded by some device. We want to operate on some subset of the columns and exclude some measurements not of interest for our analysis. | |
| int[] rowIndexes = {0,2}; int[] columnIndexes = {2,3,1,1}; System.out.println(matrix.viewSelection(rowIndexes,columnIndexes)); |
2 x 4 matrix 0 0 0 0 0 0 1 1 |
| A sort view with row flipping shows rows sorted descending by column 1: | |
| System.out.println(matrix.viewSorted(1).viewRowFlip()); | 3 x 4 matrix 1 1 0 0 1 1 0 0 0 0 0 0 |
| Last, lets combine some of the methods to stimulate imagination: | |
| matrix.viewPart(0,1,2,2).viewRowFlip().viewColumn(0).assign(2); System.out.println(matrix); |
3 x 4 matrix 0 2 0 0 1 2 0 0 1 1 0 0 |
Back to Overview
3. Semantics of Views
Find out more about the precise semantics of views and basic operations.
Back to Overview
4. Orthogonality and Polymorphism
If this section sounds trivial and obvious, you can safely skip it.
The desire for orthogonality is a desire for "plug and play". Orthogonality
demands that everything can be plugged together with everything, or, in other
words, that different things can be handled in the same way. Of course only
things that syntactically and semantically share a common set of interfaces
can be handled in the same way, or work together in the same way. Polymorphism
is an implementation mechanism supporting orthogonality. It is about being able
to exchange things without noticing any difference. Again, as long as the things
adhere to some common interface.
The common interface for matrices is defined in abstract base classes (e.g.
DoubleMatrix2D). Note that looking at the documentation
of some concrete instantiable class (e.g. DenseDoubleMatrix2D,
SparseDoubleMatrix2D, SparseRCDoubleMatrix2D![]() )
will not reveal more information than can be obtained by looking at the abstract
base classes. The convention is that concrete classes do no subsetting or
supersetting. They override methods to implement behaviour dictated by abstract
classes, or to improve performance, but they do not introduce any new functionality.
)
will not reveal more information than can be obtained by looking at the abstract
base classes. The convention is that concrete classes do no subsetting or
supersetting. They override methods to implement behaviour dictated by abstract
classes, or to improve performance, but they do not introduce any new functionality.
Although each matrix of a given rank and value type comes with dense and sparse implementations and a multitude of views, there is from the user interface perspective no difference between them. All implementations have exactly the same interface with exactly the same semantics attached. In particular, everything that "can be done" with a dense matrix can also be done with a sparse specie, and vice-versa. The same principle applies to views.
This implies that any internal or external function expecting as argument an abstract matrix (and any operation defined on an abstract matrix) can be used with any kind of matrix of the given rank and value type, whether it be dense, sparse, sub-ranged, selected, strided, sorted, flipped, transposed, or any arbitrary combination thereof. For example, dense matrices can be multiplied/assigned/transformed/compared with sparse matrices, dense stride views with dense flip views, dense sorted flipped sub-range views with sparse selection views, in all conceivable permutations. The result is a powerful and flexible tool.
Back to Overview
5. Function Objects
Function objects conveniently allow to express arbitrary functions in a generic manner. Essentially, a function object is an object that can perform a function on some arguments. It has a minimal interface: a method apply that takes the arguments, computes something and returns some result value. Function objects are comparable to function pointers in C used for call-backs. Here are some examples demonstrating how function objects can be used to
- transform a matrix A into another matrix B which is a function of the original matrix A (and optionally yet another matrix C)
- aggregate cell values or a function of them
- generate selection views for cells satisfying a given condition
- sort matrix rows or columns into a user specified order
- You will most likely use them to do many more powerful things
Usually, assign operations are heavily optimized for frequently used function
objects like plus, minus, mult, div, plusMult, minusMult, etc. Concerning the
performance of unoptimized function objects, see DoubleFunctions.
Back to Overview
6. Algorithms
As already stated, the spectrum of applications using multi-dimensional matrices is large and so is the number of operations meaningful on them. One single flat interface cannot satisfy all needs and would soon get unmanageably fat. To avoid interface bloat, it can be a good idea to separate algorithms from data structures. Special purpose algorithms, wrappers, mediators etc. should therefore go into external packages and classes. By using the common interfaces defined in abstract classes, algorithms can be implemented such that they generically work both on sparse and dense matrices and all their views. This will ensure scalability over time, as more and more features are added.
Some algorithms for formatting, sorting, statistics and partitioning, are,
for example, provided in the package cern.colt.matrix.tdouble.algo.
Back to Overview
7. Linear Algebra
See the documentation of the linear algebra package cern.colt.matrix.tdouble.algo.
Back to Overview
8. Package Organization, Naming Conventions, Policies
Class Naming / Inheritance
Have a look at the javadoc tree view to get
the broad picture. The classes for matrices of a given rank are derived from
a common abstract base class named <ValueType>Matrix<Rank>D,
which is in many ways equivalent to an "interface". 99% of the
time you will operate on these abstract classes only. For example, all 2-dimensional
matrices operating on double values are derived from DoubleMatrix2D.
This is the interface to operate on.
Class naming for concrete instantiable classes follows the schema <Property><ValueType>Matrix<Rank>D.
For example, we have a DenseDoubleMatrix2D, a
SparseDoubleMatrix2D, and so on. All concrete instantiable classes are separated into an extra package,
cern.colt.matrix.tdouble.impl, to clearly distinguish between interfaces and
implementations.
DoubleMatrix2D in turn is derived from an abstract
base class tying together all 2-dimensional matrices regardless of value type,
AbstractMatrix2D, which finally is rooted in grandmother
AbstractMatrix.
The abstract base classes provide skeleton implementations for all but few methods. Experimental data layouts can easily be implemented and inherit a rich set of functionality. For example, to implement a fully functional 2-d or 3-d matrix, only 6 abstract methods need to be overridden: getQuick, setQuick, like, like1D, viewSelectionLike.
Method Naming
In order to improve browsing and better keep an overview, the namespace of logically related operations is localized: Methods getting and setting individual cell values are named get and set. Methods constructing views are named viewXXX (e.g. viewPart). Copying/assignment methods are named copy and assignXXX. Mathematical operations are named zXXX (e.g. zMult). Generic aggregation operations are named aggregateXXX.
Convenience Methods
To keep interfaces lean and manageable, we tried to avoid littering them with
convenience methods obfuscating more fundamental concepts. Convenience operations
expressible in one to three lines of code are omitted. For example, all operations
modifying cell values modify the receiver (this) itself. There are
no methods to fill results into empty result matrices. Use idioms like result
= matrix.copy().mult(5) to achieve the same functionality. Some convenience
methods are provided in the factory classes as well as in external packages
like cern.colt.matrix.tdouble.algo.
Back to Overview
9. Performance
The following statements apply to all currently implemented features (i.e. dense and sparse matrices including all view kinds), except where indicated.
Constant factors are kept as small as possible.Views are constructed in guaranteed O(1), i.e. constant time, except for selection views and sort views: Selection views take time linear in the number of indexes, sort views take O(N*logN) on average. Getting/setting a cell value takes guaranteed constant time for dense matrices (and all their views), while it takes expected constant time for sparse hash matrices (and all their views). More specifically, on sparse hash matrices, these operations can, although highly improbable, degenerate to time linear in the number of non-zero cells. This is because of the nature of hashing: Average case behaviour is extremely good, worst case behaviour is bad.
Sparse row compressed matrices have the following
characteristics: Getting a cell value takes time O(log nzr) where nzr
is the number of non-zeros of the touched row. This is usually quick, because
typically there are only few nonzeros per row. So, in practice, get has expected
constant time. Setting a cell value takes worst-case time O(nz)
where nzr is the total number of non-zeros in the matrix. This can
be extremely slow, but if you traverse coordinates properly, each write is done
much quicker. For how to do this and other tips, see the performance
notes. ![]()
Some preliminary benchmarks can be found in the performance log.
All matrices use strided 32-bit integer arithmetic for linear cell addressing, similar to Fortran. The chosen cell addressing implementation is the key feature enabling the easy implementation and good performance of advanced views.
All methods are bounds checking, except for trusting variants of get and set called getQuick and setQuick which should and are used in expensive (often cubic) loops where it is dramatically cheaper to check bounds before entering the loop, not in the loop. Fundamentally time critical methods of dense matrices override default implementations such that iteration eliminates function calls, minimizes cell addressing overhead and gets pipelined. Some operations use processor cache oriented optimization techniques such as memory layout aware iteration, blocking of slow changing operands followed by logical optimizations such as sparsity detection.
In order to eliminate expensive call chains, views directly point to the data
without indirection, no matter how deeply nested they are. In particular they
are not implemented with delegation. In fact they are not nested at all, even
if they logically appear like that. There is largely no distinction between
views and non-views. Note that this is not true for row-compressed matrices;
their views are wrappers and do use delegation (aka call chains). ![]()
Although view objects occupy only a couple of bytes, generating temporary views at very high frequency can lead to heavy garbage collection.
To keep the overhead minimal, copying operations are highly optimized. They sometimes boil down to System.arraycopy (which is nothing else than a byte-aligned C memmove). Also note that memory access patterns (cache locality) of self-modifying matrix operations are better than for result matrix modifying operations.
Back to Overview
10. Notes
Matrices are not dynamically resizable; it is impossible to physically insert or remove cells. Some logical cell removal and insertion can be achieved by means of views. To achieve physical cell removal or insertion, a new matrix with the needed shape must be constructed and cells copied. Note, however, that there are convenience methods to do many kind of resizing operations.
Another current limitation is the inability to address more than 231 cells. This can be a problem for very large sparse matrices. 64-bit addressing is possible, but unlikely to be implemented unless there is serious demand.
Back to Overview